CVPR 2025会议公布论文录用结果,其中一项来自中国将AI应用于社交领域平台的案例研究论文被接收。详细阐述了该研究的内容、成果及意义,还介绍了CVPR会议的影响力和本次会议的投稿录用情况。
近期,IEEE国际计算机视觉与模式识别会议(Conference on Computer Vision and Pattern Recognition)CVPR 2025公布了论文录用结果。在众多优秀论文中,有一项来自中国的将AI应用于社交领域平台的案例研究论文《Teller: Real – Time Streaming Audio – Driven Portrait Animation with Autoregressive Motion Generation》(《基于自回归动作生成的实时流式音频驱动人像动画系统》)成功被接收。
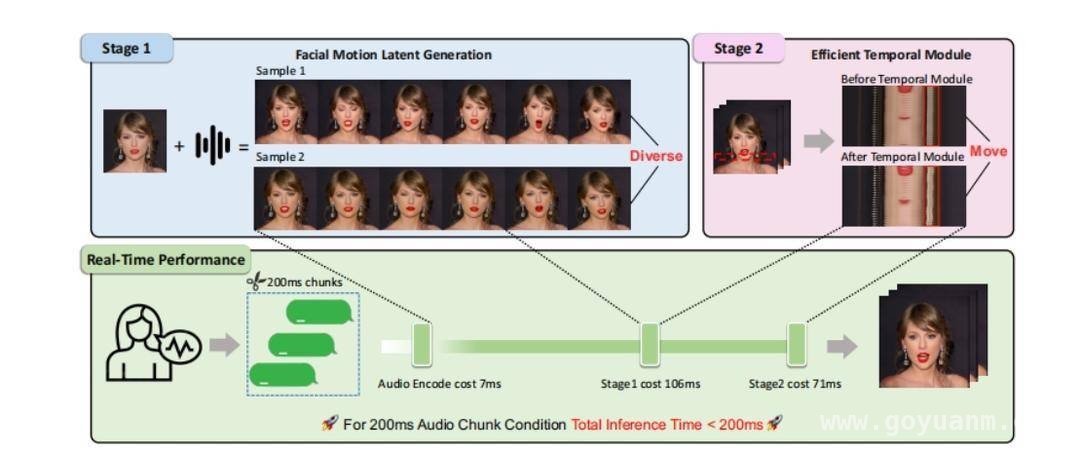
据了解,研究团队在这篇论文里提出了一个全新的面向实时音频驱动人像动画(也就是Talking Head)的自回归框架。这一框架可不简单,它不仅解决了视频画面生成耗时长这一长期困扰行业的挑战,更令人惊喜的是,它还实现了说话时头部生成以及人体各部位运动的自然性和逼真性。想象一下,在社交场景中,人物的一举一动、面部表情都如此自然,仿佛就在你眼前真实发生,这将为社交互动带来多么不一样的体验。
该论文的核心动机是解构diffusion – base的模型关键步骤,然后巧妙地用LLM和1step – diffusion进行重构,并且融合视频模态,从而让SoulX大模型成为能够同时生成文字、语音、视频的Unified Model。这就像是搭建了一个多功能的“创作工厂”,可以高效地生产出多样化的内容。
具体来说,来自Soul App的研究团队把talking head任务进行了细致的划分,分成了FMLG(面部Motion生成)、ETM(高效身体Movement生成)模块。FMLG模块基于自回归语言模型,充分利用大模型强大的学习能力和高效的多样性采样能力,能够生成准确且多样的面部Motion。也就是说,人物的面部表情可以丰富多变,喜怒哀乐都能精准呈现。而ETM模块则利用一步扩散,生成逼真的身体肌肉、饰品的运动效果,让人物的身体动作也更加生动自然,仿佛是真实人类在活动。
实验结果是检验成果的最好证明。与扩散模型相比,该方案的视频生成效率得到了大幅提升。而且从生成质量方面来看,在细微动作、面部身体动作协调度、自然度等方面均有优异表现。这充分证明了国产社交领域互联网技术在推动多模态能力构建,特别是在视觉层面能力突破上取得了阶段性的成果。这不仅是技术上的进步,更是为未来社交平台的发展打开了新的大门。
谈及研究团队所关注的视觉交互逻辑,该平台CTO陶明解释说,从交互的信息复杂度来讲,人和人面对面的沟通是信息传播方式最快、最有效的一种。“所以我们认为在线上人机交互的过程当中,需要有这样的表达方式。”在他看来,在多模态大模型能力方向基础上,该方案的提出将有助于AI构建实时生成的“数字世界”,并且能够以生动的数字形象与用户进行自然的交互。这就意味着未来用户在社交平台上可能会有更加沉浸式、真实感的交互体验。
公开资料显示,CVPR是人工智能领域最具学术影响力的顶级会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。在谷歌学术指标2024年列出的全球最有影响力的科学期刊/会议中,CVPR位列总榜第2,仅次于Nature。由此可见其在学术领域的重要地位。根据会议官方统计,本次CVPR 2025会议总投稿13008篇,录用2878篇,录用率仅为22.1%。能在如此高规格、竞争激烈的会议中脱颖而出,足以说明该中国社交平台AI研究成果的含金量。
本文介绍了CVPR 2025会议中来自中国社交平台将AI应用于社交领域的研究论文被接收一事。阐述了研究提出的自回归框架解决了视频生成耗时问题,实现人体动作自然逼真,通过划分模块提升了视频生成效率和质量。研究团队关注的视觉交互逻辑有助于构建AI“数字世界”。CVPR作为顶级学术会议,录用率低,该成果展现了国产社交领域互联网技术在多模态能力构建上的阶段性突破。